On April 7, 2005, Linus Torvalds committed eleven files and 1,244 lines to a new project with a deliberately hostile description: "Initial revision of 'git', the information manager from hell."
The repository did not yet contain the Git most developers know. There was no polished git command, no pull request, no merge queue, no web interface, no cloud runner, and no policy engine asking whether a change had passed review. There was a small collection of programs for writing objects, constructing trees, creating commits, reading a cache, and showing differences.
It was enough.
That first commit established a compact idea that would outlast almost every interface later built around it: software history could be represented as a graph of content-addressed objects, and a commit could point to a project state, its parent history, an author, a committer, and a message. Git would make the result durable and inspectable. People and institutions would decide whether to trust it.
Twenty-one years later, Git is still the substrate beneath most modern source collaboration. It is also being asked to carry a kind of work its first commit never described: changes proposed by AI agents operating in parallel, following repository instructions, invoking tools, inheriting permissions, and acting on behalf of people who may never touch the final diff.
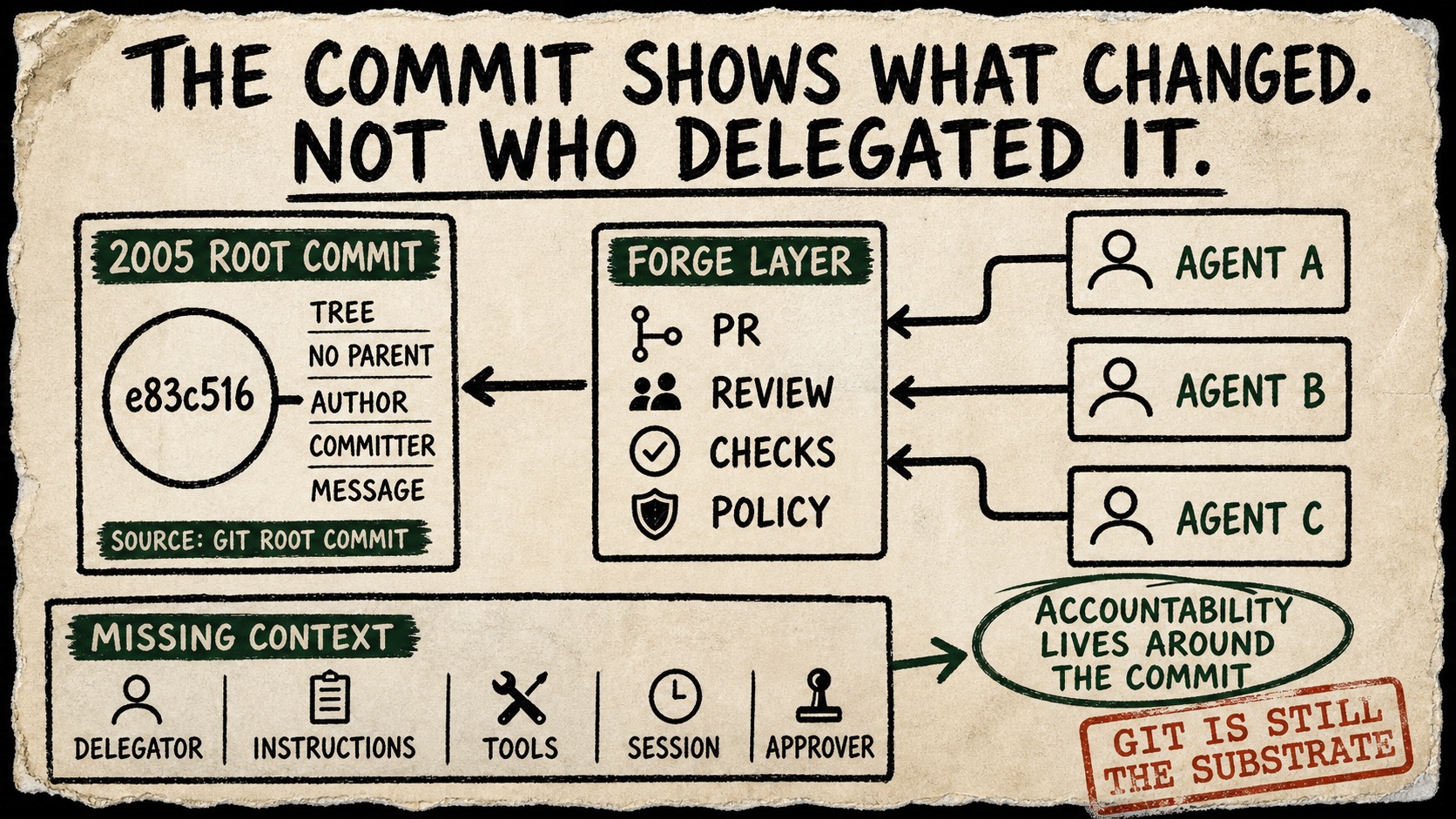
The agents fit surprisingly well into the system Git helped create. They get branches. They get worktrees. They make commits. They open pull requests. They wait for checks and review. But the fit is revealing a gap between a commit as a record of content and a commit as a record of accountability.
Git won source control by keeping that distinction small and sharp. The next era may depend on what the software world builds around it.
The first commit already drew the trust boundary
Git began during a crisis in the Linux kernel's development process. The official Git history describes how the relationship between the Linux community and the commercial BitKeeper system broke down in 2005. Torvalds and other kernel developers needed a replacement that was fast, distributed, able to support non-linear development, and capable of handling a project as large as Linux.
Torvalds's announcement to the Linux kernel mailing list on the day of the first commit was practical rather than triumphant. He described a database intended to back up all history, said the goal was eventually to reach the capabilities the project had relied on before, and noted that early merge conflicts would still need to be resolved manually. Git did not arrive as a finished product. It arrived as a recoverable foundation.
The first README called it "the stupid content tracker" and described it as a fast directory content manager. Its object model separated raw file contents, directory trees, and changesets. Names and permissions lived in trees rather than blobs. History appeared through commits that connected a resulting tree to zero, one, or more parents.
The most consequential sentence in that README was not about speed. It was about trust: Git handled content integrity, while trust had to come from outside.
That was not a defect. It was an architectural decision. Git could tell whether an object matched its identifier and whether a history graph connected. It did not need to decide whether the person named as author had authority to make the change, whether a reviewer understood it, whether a test environment was trustworthy, or whether a release should reach production.
The core commit object still reflects that boundary. The current git commit-tree documentation describes a commit constructed from a tree, parent commits, a log message, author and committer identity, and optional signing. The root commit had no parent because there was no history before it. Every later layer of social meaning could remain outside that object.
This separation made Git unusually adaptable. It also created the exact opening that today's agent systems are now trying to fill.
Git became a toolkit before it became a product
The first weeks of Git's history read like a source-control system assembling itself in public.
On April 8, the repository gained an early integrity checker. On April 9 came checkout and tree-diff tools. By April 11, revision traversal had appeared and the hidden database directory had been renamed from .dircache to .git. Patch scripts began tying the low-level commands into a usable workflow. Contributions from developers including Petr Baudis and Junio C Hamano appeared within days.
The pattern mattered. Git's early programs were deliberately small and composable. They made the graph visible and let higher-level workflows emerge around it. By May, GIT_DIR made the repository location configurable. By November, the project introduced a unified git command wrapper over the growing collection of tools. The porcelain became friendlier, but the plumbing remained available.
Git also outgrew its founder quickly. Torvalds created the core under pressure, but the public history became a community history. Junio C Hamano became the project's maintainer, and thousands of contributors spent the next two decades making the same object model work across new operating systems, network protocols, repository sizes, signing systems, storage formats, and collaboration habits.
The durability is visible in the current project. The official source page lists Git 2.54.0 as the latest release in April 2026. Its release work includes experiments in history inspection, improvements to worktrees and sparse repositories, object-source APIs, signing, tracing, and the continuing transition path away from assumptions tied to SHA-1. Git has not stopped evolving. It has kept evolving without abandoning the compact graph that made the first commit legible.
The forge gave commits a social life
Git solved distributed history. It did not, by itself, solve the institutional process of changing important software.
That work accumulated in the forge layer: GitHub, GitLab, Bitbucket, Gerrit, mailing-list workflows, CI services, release systems, and internal developer platforms. These systems turned a branch into a proposal and a commit into an object that could be discussed, checked, approved, queued, deployed, reverted, and audited.
GitHub's 2010 redesign of pull requests made this transformation explicit by combining a request to merge code with issue-like conversation and review. The pull request became a social wrapper around Git's graph: a place to explain intent, challenge an implementation, attach checks, and decide whether the change belonged.
Over time, that wrapper became policy infrastructure. Protected branches can require approving reviews, status checks, signed commits, linear history, deployments, and code-owner approval. Merge queues test proposed changes against the state they will actually enter instead of trusting that each branch remains compatible with a moving target.
None of this needed a new Git commit format. The forge could store policy, conversation, test results, and approval state around the commit. Git stayed portable. The organization supplied the trust.
This division of labor is one reason Git became so difficult to displace. Competing workflows could share the same repository format. A developer could use a command line, an IDE, a graphical client, or a hosted forge without changing the underlying history. A company could add stricter policy without forking the object model. New tools did not have to replace Git to change how software was made.
Agents arrived through the forge
AI coding agents are entering source management through the same outer layers.
GitHub's cloud coding agent works in an ephemeral GitHub Actions environment. It explores one repository, changes files, commits the result, pushes a branch, and opens a pull request for a person to review and merge. The agent is new. The delivery contract is familiar.
Local and terminal agents are converging on a similar pattern. In April, Gemini CLI merged Git worktree support for isolated parallel sessions. Each session can operate on its own branch and files while sharing repository history, reducing collisions when several agents or people work at once. OpenAI Codex added a managed worktree workflow in May and has continued refining how repository-specific files and settings reach those linked workspaces.
This is a striking reuse of a feature Git introduced long before multi-agent coding. Linked worktrees let one repository provide multiple checked-out working trees. For an agent runtime, that becomes an isolation primitive: one task, one branch, one working directory, shared object storage.
The reuse is evidence of Git's strength. An agent does not need a special AI-native repository to do useful work. It can inherit the same branching, diffing, rebasing, checking, and review practices already understood by teams.
But agents are also generating new context that does not naturally live in a commit. Repositories increasingly contain instruction files that tell agents how to behave. GitHub supports repository-wide and path-specific Copilot instructions. Codex's June 4 work on AGENTS.md loading and provenance preserves the ordered sources of instructions when a session starts, resumes, or forks.
The repository is no longer only the material an agent changes. It is also part of the control surface that tells the agent what it is allowed and expected to do.
A commit can show the result, not the delegation
Consider what Git can preserve after an agent completes a task.
The commit can identify the resulting tree. It can connect the result to its parents. It can name an author and committer, carry a message, and be signed. The diff can show exactly which tracked bytes changed. The branch and pull request can preserve discussion and checks.
But the commit does not inherently answer a growing set of questions:
- Which person delegated the work, and what authority did that person have?
- Which agent, model, runtime version, tools, and permissions produced the result?
- Which repository instructions and path-specific rules were loaded?
- Was the session resumed, forked, handed off, or assembled from multiple agents?
- What evidence did the agent inspect, and which uncertainty did it leave unresolved?
- Which tests ran, in what environment, and who accepted the remaining risk?
Some of these questions already existed for human-written code. Git author identity has never been a complete account of how a change came to exist. A developer can copy a patch, pair with a colleague, use a code generator, or make a commit on behalf of someone else. The forge and the organization carry much of the real accountability.
Agents increase the pressure because delegated work can be faster, more parallel, more persistent, and less directly observed. A person may approve a pull request containing changes created across several agent sessions without having watched any of them operate. The diff remains essential evidence, but it may be an incomplete explanation of the process that produced it.
The June 4 edition described how agent events are getting return addresses: runtimes are adding correlation and provenance so an event can be tied to the correct run, session, surface, and device. Source management is approaching the same problem at a longer timescale. A commit has an address in the history graph. Agent-made work also needs a legible address in the chain of delegation.
The new bottleneck is not producing a diff
For most of Git's life, creating a coherent patch required scarce human attention. Source-management workflows were built around reviewing a manageable stream of proposed changes.
Agents change that constraint. They can explore multiple approaches, prepare parallel branches, update tests, and keep working while the person who delegated the task does something else. The likely result is not the disappearance of review. It is more review pressure.
A pull request can prove that checks passed and record that someone clicked approve. It cannot guarantee that the reviewer understood the semantic consequences, noticed a missing requirement, or challenged a plausible but incorrect implementation. When producing code becomes cheaper, proving that a change should exist becomes more valuable.
This shifts source management toward questions of selection and accountability. Which agent branch deserves attention? Which changes can be merged together? Which decisions require human judgment? Which tests are meaningful rather than merely green? Which evidence should survive after the agent session disappears?
Merge queues and branch protection already offer part of the answer because they turn integration into a policy-governed process. Worktrees provide isolation. Pull requests provide a review boundary. Signed commits and attestations can strengthen identity and supply-chain claims. None of these alone explains the intent and delegated authority behind machine-made work.
The Git-compatible future may live above Git
The most interesting source-management experiments are not necessarily trying to replace Git's storage and interoperability. Many are trying to make the layer above it better suited to a world of abundant, parallel change.
Jujutsu is a Git-compatible version-control system that treats the working copy as a commit, records repository operations in an operation log, automatically rebases descendant work, and makes conflicts first-class objects. Its Git compatibility layer can use a colocated Git repository so changes remain visible to both systems. Its operation log preserves actions that ordinary Git history does not, allowing a user to inspect, undo, and restore source-control operations.
That richer operational history is relevant to agents. If several automated workers reshape a stack of changes, the final commits may not be the only useful record. The sequence of operations, abandoned approaches, conflict resolutions, and handoffs can matter during review or recovery.
GitButler approaches the problem from another direction. Its agent workflows tie parallel agents to branches, while its virtual-branch integration keeps additional workspace metadata outside the project's ordinary files and still produces normal Git branches at the repository boundary. The tool can change the working model without demanding that the rest of the software world stop speaking Git.
These projects do not prove that one replacement model will win. They show the design space opening around Git's stable core: richer operation logs, virtual or stacked changes, agent-session metadata, automated rebasing, and more explicit control over parallel work.
The questions ahead
Git's first commit survived because it did not try to encode every future workflow. That restraint remains a strength. It also means the next source-management contract is likely to be negotiated across repositories, agent runtimes, forges, CI systems, and organizational policy rather than delivered by one new commit field.
The unresolved questions are concrete.
Who is the author of delegated work? A human may define the goal, an agent may write the code, another agent may revise it, a maintainer may commit it, and a reviewer may authorize the merge. Those are different roles. Collapsing them into one author line loses information; preserving all of them without creating unusable noise is a design problem.
What provenance should travel with a change? Model and runtime versions, instruction sources, tool calls, test environments, approvals, and session lineage can improve auditability. They can also expose private prompts, internal paths, credentials, or sensitive reasoning. More context is not automatically more trustworthy.
How will review scale? If agents can produce more branches than people can deeply inspect, status checks and policy engines will carry more weight. That makes the quality, ownership, and transparency of those checks part of source governance rather than mere automation.
What is the durable unit of work? A commit is excellent at naming a project state. A pull request adds proposal and review. An agent session adds delegation and process. An operation log adds recovery. Future systems may need to connect all four without making repositories impossible to move or understand.
Where does accountability stop? The first Git README placed trust outside the content tracker. In the agent era, "outside" is becoming a dense stack of people, policies, models, tools, and services. Teams will need to decide which layer is allowed to say a change is ready and which person remains answerable when it is not.
The first commit is still the clue
Git's legendary first commit did not win because it predicted pull requests, cloud CI, protected branches, worktrees, merge queues, or coding agents. It won because it created a durable way to name content and connect changes into history while leaving room for those systems to grow around it.
That architecture is holding. Agents are using Git rather than routing around it. They are making its isolation primitives and collaboration conventions more valuable. At the same time, they are making visible how much meaning has always lived outside the commit.
The next era of source management may not begin with a replacement for Git. It may begin with a more demanding answer to the question Git intentionally left open: if content integrity is the tracker's job, what evidence is required before everyone else should trust the change?